Rozkład prawdopodobieństwa – w najczęstszej interpretacji (rozkład zmiennej losowej)
miara probabilistyczna
określona na
sigma-ciele
podzbiorów zbioru wartości
zmiennej losowej
(
wektora losowego
), pozwalająca przypisywać
prawdopodobieństwa
zbiorom wartości tej zmiennej, odpowiadającym
zdarzeniom losowym
. Formalnie rozkład prawdopodobieństwa może być jednak rozpatrywany także bez stosowania zmiennych losowych.
Definicja
Rozkładem prawdopodobieństwa nazywa się dowolną miarę probabilistyczną  określoną na
σ-ciele
podzbiorów borelowskich
pewnej
przestrzeni polskiej
. Dla rozkładów ciągłych często jest nią zbiór liczb rzeczywistych
określoną na
σ-ciele
podzbiorów borelowskich
pewnej
przestrzeni polskiej
. Dla rozkładów ciągłych często jest nią zbiór liczb rzeczywistych 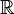 (tzw. rozkład jednowymiarowy) lub
przestrzeń euklidesowa
(tzw. rozkład jednowymiarowy) lub
przestrzeń euklidesowa
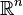 dla pewnej liczby naturalnej
dla pewnej liczby naturalnej  (rozkład wielowymiarowy).
(rozkład wielowymiarowy).
Zastosowanie dla zmiennych losowych
Zwykle rozważa się tzw.
przestrzeń probabilistyczną
, złożoną z
przestrzeni zdarzeń elementarnych
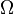 , określonego na niej σ-ciała
, określonego na niej σ-ciała 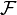 , którego elementy są nazywane zdarzeniami losowymi, oraz miary probabilistycznej , przyporządkowującej zdarzeniom liczby zwane prawdopodobieństwami. Tak określone prawdopodobieństwa są jednak niewygodne do badania, gdyż może być dowolnym zbiorem, nawet bez zadanych jakichkolwiek relacji między jego elementami.
, którego elementy są nazywane zdarzeniami losowymi, oraz miary probabilistycznej , przyporządkowującej zdarzeniom liczby zwane prawdopodobieństwami. Tak określone prawdopodobieństwa są jednak niewygodne do badania, gdyż może być dowolnym zbiorem, nawet bez zadanych jakichkolwiek relacji między jego elementami.
Wprowadza się zatem
funkcję mierzalną
zwaną
zmienną losową
, która przyporządkowuje elementom przestrzeni zdarzeń elementarnych elementy pewnej
przestrzeni mierzalnej
 o pożądanych właściwościach[1]. Najczęściej wykorzystuje się przestrzeń euklidesową
o pożądanych właściwościach[1]. Najczęściej wykorzystuje się przestrzeń euklidesową 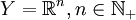 a zmienną nazywa się wówczas
wektorem losowym
. Czasem miano zmiennej losowej rezerwuje się tylko dla przypadku jednowymiarowego
a zmienną nazywa się wówczas
wektorem losowym
. Czasem miano zmiennej losowej rezerwuje się tylko dla przypadku jednowymiarowego  .
.
Obrazem
każdego zdarzenia losowego (elementu rodziny) poprzez zmienną losową 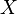 jest mierzalny podzbiór . Mierzalne podzbiory tworzą także σ-ciało
jest mierzalny podzbiór . Mierzalne podzbiory tworzą także σ-ciało  . Ponieważ zmienna losowa nie musi być
funkcją różnowartościową
, więc ten sam zbiór mierzalny
. Ponieważ zmienna losowa nie musi być
funkcją różnowartościową
, więc ten sam zbiór mierzalny  można w ogólnym przypadku otrzymać z wielu różnych zdarzeń o różnych prawdopodobieństwach. Aksjomaty σ-ciała zapewniają, że wśród tych zdarzeń jest także ich
suma
i do niej jest przypisane największe prawdopodobieństwo. Suma ta jest równa
przeciwobrazowi
zbioru
można w ogólnym przypadku otrzymać z wielu różnych zdarzeń o różnych prawdopodobieństwach. Aksjomaty σ-ciała zapewniają, że wśród tych zdarzeń jest także ich
suma
i do niej jest przypisane największe prawdopodobieństwo. Suma ta jest równa
przeciwobrazowi
zbioru  , czyli
, czyli  .
.
Rozkład zmiennej losowej to funkcja  określona na wzorem
określona na wzorem  .
.
Rozkład jest nową miarą probabilistyczną. Jest on w przestrzeni stanów odpowiednikiem miary probabilistycznej .
Uwaga: Zapis gdzie jest zdarzeniem a nie zmienną losową jest stosowany na oznaczenie
prawdopodobieństwa warunkowego
.
Wyróżnia się niżej omówione rozkłady ciągłe i dyskretne, jednak należy pamiętać, iż oprócz nich istnieją także rozkłady nie mieszczące się w żadnej z tych kategorii – na przykład rozkład o
dystrybuancie Cantora
.
Rozkład ciągły
Jeżeli istnieje funkcja  , taka że
, taka że

(
całka Lebesgue'a
) dla dowolnego zbioru borelowskiego  , to funkcję tę nazywa się gęstością (rozkładu) prawdopodobieństwa lub funkcją gęstości prawdopodobieństwa. Nazwa pochodzi od intuicji fizycznych, zob.
gęstość masy
. O rozkładzie mającym gęstość mówi się, że jest ciągły (lub typu ciągłego).
, to funkcję tę nazywa się gęstością (rozkładu) prawdopodobieństwa lub funkcją gęstości prawdopodobieństwa. Nazwa pochodzi od intuicji fizycznych, zob.
gęstość masy
. O rozkładzie mającym gęstość mówi się, że jest ciągły (lub typu ciągłego).
Powyższa definicja jest poprawna dla dowolnych rozkładów prawdopodobieństwa, także wielowymiarowych – wówczas 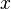 jest wektorem.
jest wektorem.
Rozkład zmiennej losowej spełniający powyższe warunki definiuje się analogicznie. O zmiennej losowej również mówi się wówczas, iż jest ciągła (lub typu ciągłego).
Rozkład dyskretny
Rozkład P nazywa się dyskretnym, jeśli jest skupiony na zbiorze przeliczalnym, tzn. istnieje zbiór (co najwyżej) przeliczalny  dla którego P(S) = 1. Jeżeli
dla którego P(S) = 1. Jeżeli
 oraz pi = P({si}) dla każdego
oraz pi = P({si}) dla każdego 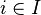 ,
,
to dla dowolnego zbioru borelowskiego A
 ,
,
gdzie  to
indykator
(funkcja charakterystyczna) zbioru A.
to
indykator
(funkcja charakterystyczna) zbioru A.
Zatem zbiór par  jednoznacznie wyznacza rozkład P. Stąd dowolny zbiór tej postaci, gdzie pi > 0 oraz
jednoznacznie wyznacza rozkład P. Stąd dowolny zbiór tej postaci, gdzie pi > 0 oraz  (co wynika z własności rozkładu), nazywa się czasami rozkładem (dyskretnym). Odwzorowanie
(co wynika z własności rozkładu), nazywa się czasami rozkładem (dyskretnym). Odwzorowanie 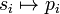 , oznaczane
, oznaczane  , nosi nazwę funkcji masy prawdopodobieństwa i jest ono dyskretnym odpowiednikiem gęstości prawdopodobieństwa.
, nosi nazwę funkcji masy prawdopodobieństwa i jest ono dyskretnym odpowiednikiem gęstości prawdopodobieństwa.
Dyskretna zmienna losowa
X to zmienna losowa o rozkładzie dyskretnym. Wówczas można go zdefiniować podobnie jak wyżej równością
- PX({xi}) = P(X − 1(A)),
jednakże w tym wypadku zachodzi dodatkowo
 ,
,
gdzie  jest
zbiorem wszystkich wartości przyjmowanych przez zmienną
X.
jest
zbiorem wszystkich wartości przyjmowanych przez zmienną
X.
Dystrybuanta
Badanie rozkładu jako miary jest zadaniem dość trudnym, jednak można je znacząco uprościć wprowadzając funkcję dystrybuanty, która całkowicie go opisuje i jest funkcją przestrzeni euklidesowej w przedział [0,1].
Dystrybuanta rozkładu jednowymiarowego
Dystrybuanta jednowymiarowego rozkładu (prawdopodobieństwa) to funkcja  , zdefiniowana wzorem:
, zdefiniowana wzorem:
![F_P(t) = P((-\infty, t])](http://upload.wikimedia.org/math/6/a/a/6aaabe60b529833a33f0740278202f26.png) .
.
Dystrybuanta (rozkładu) zmiennej losowej , to dystrybuanta  , oznaczana zwykle symbolem
, oznaczana zwykle symbolem  , otrzymana z rozkładu tej zmiennej losowej:
, otrzymana z rozkładu tej zmiennej losowej:

Dystrybuanta w pełni wyznacza rozkład, tzn. dwie zmienne o tej samej dystrybuancie muszą mieć ten sam rozkład; obrazuje to poniższy przykład.
Jeśli rozkład ma gęstość  , jego dystrubuanta
, jego dystrubuanta  wyraża się wzorem:
wyraża się wzorem:
 .
.
Przykład
Niech  będzie modelem doświadczenia losowego polegającego na rzucie monetą, które może z jednakowym prawdopodobieństwem dać dwa wyniki: orła i reszkę. Stąd
będzie modelem doświadczenia losowego polegającego na rzucie monetą, które może z jednakowym prawdopodobieństwem dać dwa wyniki: orła i reszkę. Stąd
 oraz
oraz  .
.
Jeżeli zmienna 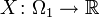 jest określona równościami
jest określona równościami
 oraz
oraz  ,
,
to jej rozkład jest określony następująco:
 ,
,
funkcja masy prawdopodobieństwa ma z kolei postać:
 ,
,
co oznacza, że zmienna losowa odwzorowuje zdarzenia
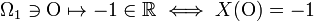 ,
,
oraz zachowuje prawdopodobieństwo określone na  przekształcając je w rozkład określony na
przekształcając je w rozkład określony na  .
.
Niech  będzie modelem opisującym jak wyżej rzut monetą poszerzone o dodatkowy wynik: upadek na kant, który
prawie na pewno
się nie zdarzy. Jeżeli
będzie modelem opisującym jak wyżej rzut monetą poszerzone o dodatkowy wynik: upadek na kant, który
prawie na pewno
się nie zdarzy. Jeżeli
 oraz
oraz  ,
,
to zmienna losowa  określona równościami
określona równościami
 oraz
oraz  ,
,
będzie miała taki sam rozkład  (oraz funkcję masy) co zmienna określona wyżej, mimo iż są one różne.
(oraz funkcję masy) co zmienna określona wyżej, mimo iż są one różne.
Z definicji dystrybuanty wynika, iż prawdopodobieństwo zdarzenia

dane jest wzorem
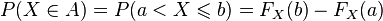 .
.
Dystrybuanta zmiennej to funkcja ![F_X\colon \mathbb R \to [0, 1]](http://upload.wikimedia.org/math/c/7/7/c77ce5f648448844cc40589138a772cd.png) określona wzorem
określona wzorem

Warto zauważyć, iż dystrybuanta  zmiennej dana jest tym samym wzorem co dystrybuanta .
zmiennej dana jest tym samym wzorem co dystrybuanta .
Dystrybuanta rozkładu wielowymiarowego
Jeśli jest
wektorem losowym
, tzn.  , to zmienia się nieco postać dystrybuanty. Rozważa się wówczas przedziały wielowymiarowe, tzn. zbiory będące
iloczynami kartezjańskimi
przedziałów prostej postaci
, to zmienia się nieco postać dystrybuanty. Rozważa się wówczas przedziały wielowymiarowe, tzn. zbiory będące
iloczynami kartezjańskimi
przedziałów prostej postaci
![(-\infty, t_1] \times (-\infty, t_2] \times \dots \times (-\infty, t_n]](http://upload.wikimedia.org/math/0/0/9/009149abe42389ac1031082ecd5c4dae.png) ;
;
dystrybuanta  takiego zdarzenia zapisywana jest zwykle jako
takiego zdarzenia zapisywana jest zwykle jako
![F_P(t_1, t_2, \dots, t_n) = P((-\infty, t_1] \times (-\infty, t_2] \times \dots \times (-\infty, t_n])](http://upload.wikimedia.org/math/b/f/7/bf70471dc1493a846825a475935db5d1.png) .
.
Stosuje się następujący zapis dystrybuanty rozkładu zmiennej losowej:
 ,
,
gdzie 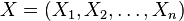 . Jeżeli przyjmie się
. Jeżeli przyjmie się  , to zapis
, to zapis

nie prowadzi zwykle do większych nieporozumień.
Jeśli rozkład wielowymiarowy ma gęstość , jego dystrybuanta wyraża się wzorem (całka Lebesgue'a):
![F_P(t) = \int\limits_{(-\infty, t_1] \times (-\infty, t_2] \times \dots \times (-\infty, t_n]}~f(t)\;dt](http://upload.wikimedia.org/math/5/f/9/5f916ff5d21af4cf69ead40376f28729.png) .
.
Zwykle wzór ten spotyka się w prostszej wersji, choć o mniejszym zakresie stosowalności (nie każdą całkę Lebesgue'a da się w ten sposób rozbić):

Dodatkowe definicje
Zmienna losowa ma rozkład osobliwy (singularny), jeśli ma ciągłą dystrybuantę i istnieje zbiór 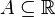 , który ma
zerową
miarę Lebesgue'a
, ale jednostkowy rozkład (miarę) prawdopodobieństwa, tzn.
, który ma
zerową
miarę Lebesgue'a
, ale jednostkowy rozkład (miarę) prawdopodobieństwa, tzn.  oraz
oraz 
Rozkłady skoncentrowane na zbiorze punktów postaci  , gdzie
, gdzie  nazywa się arytmetycznymi. To, iż rozkład jest skupiony na zbiorze
nazywa się arytmetycznymi. To, iż rozkład jest skupiony na zbiorze  jest równoważne temu, iż jego
funkcja charakterystyczna
jest równoważne temu, iż jego
funkcja charakterystyczna
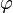 ma
okres
równy
ma
okres
równy  bądź
bądź 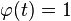 dla pewnego
dla pewnego  . Z obserwacji funkcji charakterystycznych wynika, iż arytmetyczne są rozkłady: geometryczny, Bernoulliego i Poissona; rozkłady jedno- i dwupunktowe są przesuniętymi rozkładami tego typu.
. Z obserwacji funkcji charakterystycznych wynika, iż arytmetyczne są rozkłady: geometryczny, Bernoulliego i Poissona; rozkłady jedno- i dwupunktowe są przesuniętymi rozkładami tego typu.
Popularne rozkłady
Rozkłady ciągłe
-
rozkład beta
,
-
rozkład χ²
,
-
rozkład Cauchy'ego
,
-
rozkład Erlanga
,
-
rozkład F Snedecora
,
-
rozkład gamma
,
-
rozkład Gumbela
,
-
rozkład Weibulla
,
-
rozkład jednostajny ciągły
(prostokątny),
- rozkład Laplace'a,
- rozkład Leviego,
-
rozkład logarytmiczno-normalny
,
-
rozkład normalny
(Gaussa),
-
rozkład normalny wielowymiarowy
,
-
rozkład trójkątny
,
-
rozkład t-Studenta
,
-
rozkład wykładniczy
.
Rozkłady dyskretne
Statystyka
Jeśli mamy na myśli rzeczywiste prawdopodobieństwa wystąpienia danej wartości cechy w
populacji
, to mówimy o rozkładzie w populacji. Jeśli mamy na myśli prawdopodobieństwa wystąpienia danej cechy wyznaczone podczas
badania statystycznego
, to mówimy o
rozkładzie empirycznym
.
Przypisy
- ↑ Ściślej musi to być funkcja
 -mierzalna, gdzie
-mierzalna, gdzie 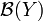 jest rodziną podzbiorów borelowskich przestrzeni . Jako zwykle wybiera się jedną z tzw.
przestrzeni polskich
, do których zaliczają się w szczególności przestrzenie euklidesowe.
jest rodziną podzbiorów borelowskich przestrzeni . Jako zwykle wybiera się jedną z tzw.
przestrzeni polskich
, do których zaliczają się w szczególności przestrzenie euklidesowe.
Zobacz też